
Escrito por:
Lina María García – Fundación Universitaria Konrad Lorenz – linam.garciag@konradlorenz.edu.co- Contadora Pública
Javier Andrey Ávila – Fundación Universitaria Konrad Lorenz – javiera.avilag@konradlorenz.edu.co -Administradora de Empresas
Marly Pedraza – Fundación Universitaria Konrad Lorenz marly.pedrazas@konradlorenz.edu.co -Administradora de Empresas
Jonathan Pérez – Fundación Universitaria Konrad Lorenz- jonathana.perez@konradlorenz.edu.co- Lorenz Licenciado en Matemáticas
Asesoría:
Camilo Matson Hernández– Docente de la especialización analítica estratégica de datos-Magister en Economía- Fundación Universitaria Konrad Lorenz
Este artículo obedece a la opinión de su autor. Positiva Compañía de Seguros S.A. no se hace responsable por los puntos de vista que allí se expresen. El material contenido en este sitio web es de dominio público y puede reproducirse parcial o totalmente de manera gratuita, siempre y cuando se mencione la fuente.

Metodología
El fraude es una conducta que nos afecta e involucra a todos, genera grandes pérdidas económicas, ocasiona deterioro en la calidad de vida de los habitantes, limita las oportunidades y protección en sus hogares, provoca crisis e inestabilidad en las organizaciones, familias, instituciones y en todo un país. Esta mala práctica impacta y trae consecuencias en la salud física, mental y emocional de quienes han sido víctimas.
En Colombia, el sector asegurador ha detectado el incremento ilegal del número de empresas que ofrecen afiliación a las Administradoras de Riesgos Laborales (ARL), donde empresas se prestan como intermediarios ilegales no autorizados por el Ministerio de Salud y Protección Social, realizando las afiliaciones con tarifas inferiores a las establecidas por la Ley.
En relación con la idea anterior, algunas compañías aseguradoras colombianas crearon el Instituto Nacional de Investigación y Prevención del Fraude (INIF), encargado de investigar y generar modelos que identifiquen características del defraudador, con el fin de mitigar el fraude., Dicha institución menciona que las acciones fraudulentas cometidas en el país generan un costo alrededor de 4.2 billones de pesos anuales.
Teniendo en cuenta la problemática anterior, se propuso un modelo predictivo con base en el algoritmo de red neuronal que permita identificar características de fraude en las afiliaciones que realizan las empresas irregulares dentro de una administradora de riesgo laborales (Positiva Compañía de Seguros S.A.).

La metodología CRISP – DM (Cross-Industry Standard Process for Data Mining) permitió conocer el modelo de negocio de la compañía de seguros, el entendimiento de la información y la preparación del modelo predictivo para esta investigación.
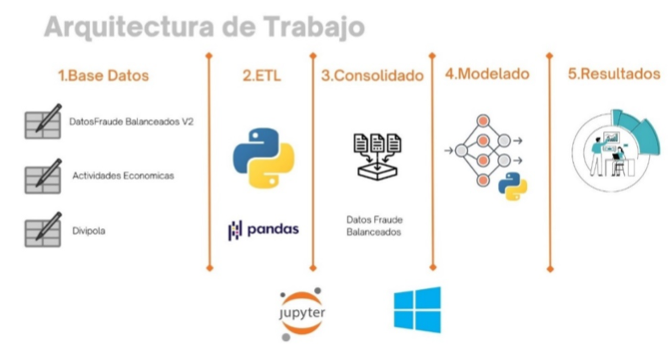
A partir de la base de datos suministrada por la compañía de seguros, se evidenció que la participación de las empresas irregulares corresponde al 0,66% de 422.097 registros.

Resultados y Análisis
Se aplicaron algoritmos de clasificación como Regresión logística y Árbol de clasificación dando como resultado una precisión de clasificar correctamente las empresas fraudulentas del 65% y 4% respectivamente, por este motivo se propuso aplicar una red neuronal multicapa con el fin de mejorar dicha métrica.
A partir de algoritmo seleccionado se aplicó la técnica de SMOTE a la data de entrenamiento que correspondió al 70% de los registros, esto con fin de igualar la cantidad de registros entre regulares e irregulares. Esta técnica se basa en el algoritmo K vecinos más cercanos, el cual permite crear datos sintéticos con características similares como datos que “ayudarían” a una mejor ejecución del algoritmo de red neuronal.
En este caso al emplear la técnica de balanceo, la data de entrenamiento quedó conformada por 295.833 registros para cada una de las categorías (fraudulentas y no fraudulentas), posteriormente se emplea la red multicapa explorando los parámetros que la conforman, donde se propone utilizar una red con 2 capas ocultas de 50 y 25 neuronas respectivamente.
Con el objetivo de evaluar el desempeño del algoritmo se parte de la matriz de confusión, donde se muestra el cruce entre las predicciones realizadas por el modelo y los valores reales. Caso particular 678 empresas fueron bien clasificadas como irregulares.
| Predicho | ||||
| Regular | Irregular | Total | ||
| Real | Regular | 125.521 | 192 | 125.713 |
| Irregular | 202 | 678 | 880 | |
| Total | 125.723 | 1.170 | 126.593 | |

De acuerdo con los resultados anteriores se determinan las métricas de clasificación, como los son la exactitud que a pesar de mostrar un resultado óptimo del 100% cuenta con inconvenientes en la información, ya que el algoritmo no puede realizar una diferenciación entre la clase minoritaria (irregular), por lo tanto, no es una buena métrica de calidad.
Por otro lado, la precisión del algoritmo indica que se clasifica correctamente el 78% de empresas fraudulentas , el recall muestra que la capacidad del algoritmo para detectar una empresa irregular es del 77%.
|
Métricas-Clase Fraude |
Sensibilidad (Recall) | 0,77 |
| Especificidad (Specifity) | 0,99 | |
| Precisión | 0,78 | |
| Exactitud (Accuary) | 1 | |
| F1-score | 0,77 |
Finalmente, otra medida utilizada es determinar al área de la curva ROC, a mayor valor mejor es la clasificación realizada, esto se puede ver reflejado en la siguiente gráfica:
Como el valor es 0.88, entonces hay un 88% de probabilidad de que el algoritmo distinga bien entre empresas fraudulentas y no fraudulentas.
Conclusiones
Mediante el análisis exploratorio de cada una de las variables se identificaron características correspondientes a empresas fraudulentas, entre ellas que la mayoría se concentran en el departamento de Antioquia y Bogotá D.C. Así mismo, el 21% y 10% de las empresas sospechosas de fraude están en actividades inmobiliarias empresariales-alquiler y construcción respectivamente. Adicionalmente, el 17% de las empresas con indicios de fraude son grandes y el 26% pertenecen a riesgo 1.
Al analizar la base de datos suministrada y emplear el algoritmo de red neuronal perceptrón multicapa con 2 capas de 24 N y 15 N, el desempeño del algoritmo indicó mediante la métrica de recall y precisión que clasifica correctamente el 78 % de las empresas fraudulentas y logra detectar en un 77% una empresa irregular, por lo que concluimos que esta problemática se puede mitigar al implementar diferentes modelos analíticos.
Utilizar estas herramientas tecnológicas permiten detectar en tiempo real la vinculación de empresas fraudulentas, de tal manera que se pueda hacer un análisis previo más detallado, así como implementar estrategias de seguimiento y control en la afiliación de compañías, con el fin de minimizar el fraude.




